To mark our 150th year, we’re revisiting the Popular Science stories (both hits and misses) that helped define scientific progress, understanding, and innovation—with an added hint of modern context. Explore the entire From the Archives series and check out all our anniversary coverage here.
Social psychologist Frank Rosenblatt had such a passion for brain mechanics that he built a computer model fashioned after a human brain’s neural network, and trained it to recognize simple patterns. He called his IBM 704-based model Perceptron. A New York Times headline called it an “Embryo of Computer Designed to Read and Grow Wiser.” Popular Science called Perceptrons “Machines that learn.” At the time, Rosenblatt claimed “it would be possible to build brains that could reproduce themselves on an assembly line and which would be conscious of their existence.” The year was 1958.
Many assailed Rosenblatt’s approach to artificial intelligence as being computationally impractical and hopelessly simplistic. A critical 1969 book by Turing Award winner Marvin Minsky marked the onset of a period dubbed the AI winter, when little funding was devoted to such research—a short revival in the early ‘80s notwithstanding.
In a 1989 Popular Science piece, “Brain-Style Computers,” science and medical writer Naomi Freundlich was among the first journalists to anticipate the thaw of that long winter, which lingered into the ‘90s. Even before Geoffrey Hinton, considered one of the founders of modern deep learning techniques, published his seminal 1992 explainer in Scientific American, Freundlich’s reporting offered one of the most comprehensive insights into what was about to unfold in AI in the next two decades.
“The resurgence of more-sophisticated neural networks,” wrote Freundlich, “was largely due to the availability of low-cost memory, greater computer power, and more-sophisticated learning laws.” Of course, the missing ingredient in 1989 was data—the vast troves of information, labeled and unlabeled, that today’s deep-learning neural networks inhale to train themselves. It was the rapid expansion of the internet, starting in the late 1990s, that made big data possible and, coupled with the other ingredients noted by Freundlich, unleashed AI—nearly half a century after Rosenblatt’s Perceptron debut.
“Brain-style computers” (Naomi J. Freundlich, February 1989)
I walked into the semi-circular lecture hall at Columbia University and searched for a seat within the crowded tiered gallery. An excited buzz petered off to a few coughs and rustling paper as a young man wearing circular wire-rimmed glasses walked toward the lectern carrying a portable stereo tape player under his arm. Dressed in a tweed jacket and corduroys, he looked like an Ivy League student about to play us some of his favorite rock tunes. But instead, when he pushed the “on” button, a string of garbled baby talk-more specifically, baby-computer talk-came flooding out. At first unintelligible, really just bursts of sounds, the child-robot voice repeated the string over and over until it became ten distinct words.
“This is a recording of a computer that taught itself to pronounce English text overnight,” said Terrence Sejnowski, a biophysicist at Johns Hopkins University. A jubilant crowd broke into animated applause. Sejnowski had just demonstrated a “learning” computer, one of the first of a radically new kind of artificial-intelligence machine.
Called neural networks, these computers are loosely modeled after the interconnected web of neurons, or nerve cells, in the brain. They represent a dramatic change in the way scientists are thinking about artificial intelligence- a leaning toward a more literal interpretation of how the brain functions. The reason: Although some of today’s computers are extremely powerful processors that can crunch numbers at phenomenal speeds, they fail at tasks a child does with ease-recognizing faces, learning to speak and walk, or reading printed text. According to one expert, the visual system of one human being can do more image processing than all the supercomputers in the world put together. These kinds of tasks require an enormous number of rules and instructions embodying every possible variable. Neural networks do not require this kind of programming, but rather, like humans, they seem to learn by experience.
For the military, this means target-recognition systems, self-navigating tanks, and even smart missiles that chase targets. For the business world, neural networks promise handwriting-and face-recognition systems and computer loan officers and bond traders. And for the manufacturing sector, quality-control vision systems and robot control are just two goals.
Interest in neural networks has grown exponentially. A recent meeting in San Diego brought 2,000 participants. More than 100 companies are working on neural networks, including several small start-ups that have begun marketing neural-network software and peripherals. Some computer giants, such as IBM, AT&T, Texas Instruments, Nippon Electric Co., and Fujitsu, are also going full ahead with research. And the Defense Advanced Research Projects Agency (or DARPA) released a study last year that recommended neural-network funding of $400 million over eight years. It would be one of the largest programs ever undertaken by the agency.
Ever since the early days of computer science, the brain has been a model for emerging machines. But compared with the brain, today’s computers are little more than glorified calculators. The reason: A computer has a single processor operating on programmed instructions. Each task is divided into many tiny steps that are performed quickly, one at a time. This pipeline approach leaves computers vulnerable to a condition commonly found on California freeways: One stalled car-one unsolvable step-can back up traffic indefinitely. The brain, in contrast, is made up of billions of neurons, or nerve cells, each connected to thousands of others. A specific task enlists the activity of whole fields of neurons; the communication pathways among them lead to solutions.
The excitement over neural networks is not new and neither are the “brain makers.” Warren S. McCulloch, a psychiatrist at the Universities of Illinois and Chicago, and his student Walter H. Pitts began studying neurons as logic devices in the early 1940s. They wrote an article outlining how neurons communicate with each other electrochemically: A neuron receives inputs from surrounding cells. If the sum of the inputs is positive and above a certain preset threshold, the neuron will fire. Suppose, for example, that a neuron has a threshold of two and has two connections, A and B. The neuron will be on only if both A and B are on. This is called a logical “and” operation. Another logic operation called the “inclusive or” is achieved by setting the threshold at one: If either A or B is on, the neuron is on. If both A and B are on, then the neuron is also on.
In 1958 Cornell University psychologist Frank Rosenblatt used hundreds of these artificial “neurons” to develop a two-layer pattern-learning network called the perceptron. The key to Rosenblatt’s system was that it learned. In the brain, learning occurs predominantly by modification of the connections between neurons. Simply put, if two neurons are active at once and they’re connected, then the synapses (connections) between them will get stronger. This learning rule is called Hebb’s rule and was the basis for learning in the perceptron. Using Hebb’s rule, the network appears to “learn by experience” because connections that are used often are reinforced. The electronic analog of a synapse is a resistor and in the perceptron resistors controlled the amount of current that flowed between transistor circuits.
Other simple networks were also built at this time. Bernard Widrow, an electrical engineer at Stanford University, developed a machine called Adaline (for adaptive linear neurons) that could translate speech, play blackjack, and predict weather for the San Francisco area better than any weatherman. The neural network field was an active one until 1969.
In that year the Massachusetts Institute of Technology’s Marvin Minsky and Seymour Papert—major forces in the rule-based AI field—wrote a book called Perceptrons that attacked the perceptron design as being “too simple to be serious.” The main problem: The perceptron was a two-layer system-input led directly into output-and learning was limited. ”What Rosenblatt and others wanted to do basically was to solve difficult problems with a knee-jerk reflex,” says Sejnowski.
The other problem was that perceptrons were limited in the logic operations they could execute, and therefore they could only solve clearly definable problems–deciding between an L and a T for example. The reason: Perceptrons could not handle the third logic operation called the “exclusive or.” This operation requires that the logic unit turn on if either A or B is on, but not if they both are.
According to Tom Schwartz, a neural-network consultant in Mountain View, Calif., technology constraints limited the success of perceptrons. “The idea of a multilayer perceptron was proposed by Rosenblatt, but without a good multilayer learning law you were limited in what you could do with neural nets.” Minsky’s book, combined with the perceptron’s failure to achieve developers’ expectations, squelched the neural-network boom. Computer scientists charged ahead with traditional artificial intelligence, such as expert systems.
Underground connections
During the “dark ages” as some call the 15 years between the publication of Minsky’s Perceptrons and the recent revival of neural networks, some die-hard “connectionists” –neural-network adherent–prevailed. One of them was physicist John J. Hopfield, who splits his time between the California Institute of Technology and AT&T Bell Laboratories. A paper he wrote in 1982 described mathematically how neurons could act collectively to process and store information, comparing a problem’s solution in a neural network with achieving the lowest energy state in physics. As an example, Hopfield demonstrated how a network could solve the “traveling salesman” problem- finding the shortest route through a group of cities a problem that had long eluded conventional computers. This paper is credited with reinvigorating the neural network field. “It took a lot of guts to publish that paper in 1982,” says Schwartz. “Hopfield should be known as the fellow who brought neural nets back from the dead.”
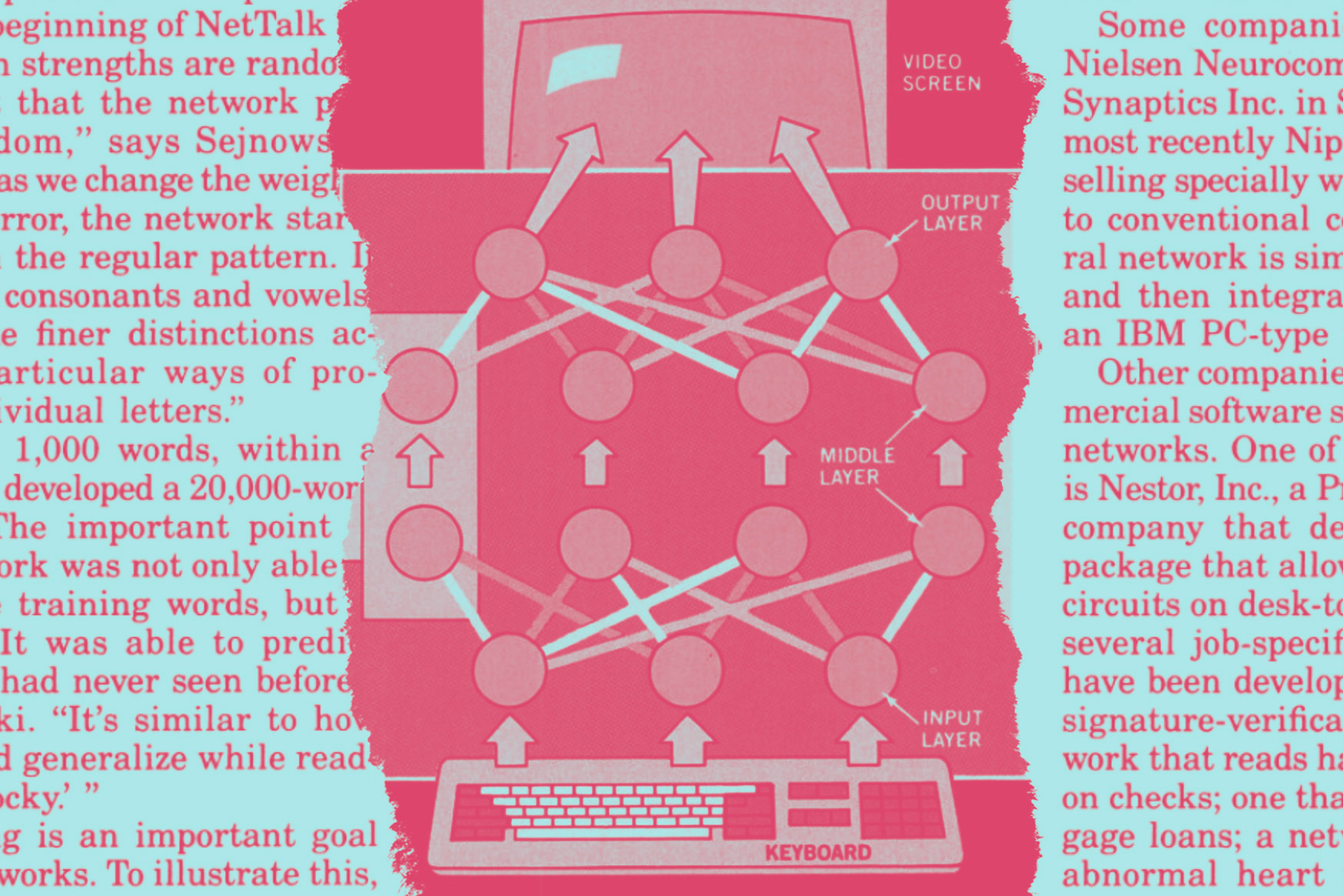
The resurgence of more-sophisticated neural networks was largely due to the availability of low-cost memory, greater computer power, and more-sophisticated learning laws. The most important of these learning laws is some- thing called back-propagation, illustrated dramatically by Sejnowski’s NetTalk, which I heard at Columbia.
With NetTalk and subsequent neural networks, a third layer, called the hidden layer, is added to the two-layer network. This hidden layer is analogous to the brain’s interneurons, which map out pathways between the sensory and motor neurons. NetTalk is a neural-network simulation with 300 processing units-representing neurons- and over 10,000 connections arranged in three layers. For the demonstration I heard, the initial training input was a 500-word text of a first-grader’s conversation. The output layer consisted of units that encoded the 55 possible phonemes-discreet speech sounds-in the English language. The output units can drive a digital speech synthesizer that produces sounds from a string of phonemes. When NetTalk saw the letter N (in the word “can” for example) it randomly (and erroneously) activated a set of hidden layer units that signaled the output “ah.” This output was then compared with a model: a correct letter-to-phoneme translation, to calculate the error mathematically. The learning rule, which is actually a mathematical formula, corrects this error by “apportioning the blame”-reducing the strengths of the connections between the hidden layer that corresponds to N and the output that corresponds to “ah.” “At the beginning of NetTalk all the connection strengths are random, so the output that the network produces is random,” says Sejnowski. “Very quickly as we change the weights to minimize error, the network starts picking up on the regular pattern. It distinguishes consonants and vowels, and can make finer distinctions according to particular ways of pronouncing individual letters.”
Trained on 1,000 words, within a week NetTalk developed a 20,000-word dictionary. “The important point is that the network was not only able to memorize the training words, but it generalized. It was able to predict new words it had never seen before,” says Sejnowski. “It’s similar to how humans would generalize while reading ‘Jabberwocky.’ “
Generalizing is an important goal for neural networks. To illustrate this, Hopfield described a munition identification problem he worked on two summers ago in Fort Monmouth, N.J. “Let’s say a battalion needs to identify an unexploded munition before it can be disarmed,” he says. “Unfortunately there are 50,000 different kinds of hardware it might be. A traditional computer would make the identification using a treelike decision process,” says Hopfield. ”The first decision could be based on the length of the munition.” But there’s one problem: “It turns out the munition’s nose is buried in the sand, and obviously a soldier can’t go out and measure how long it is. Although you’ve got lots of information, there are always going to be pieces that you are not allowed to get. As a result you can’t go through a treelike structure and make an identification.”
Hopfield sees this kind of problem as approachable from a neural-network point of view. “With a neural net you could know ten out of thirty pieces of information about the munition and get an answer.”
Besides generalizing, another important feature of neural networks is that they “degrade gracefully.” The human brain is in a constant state of degradation-one night spent drinking alcohol consumes thousands of brain cells. But because whole fields of neurons contribute to every task, the loss of a few is not noticeable. The same is true with neural networks. David Rumelhart, a psychologist and neural-network researcher at Stanford University, explains: “The behavior of the network is not determined by one little localized part, but in fact by the interactions of all the units in the network. If you delete one of the units, it’s not terribly important. Deleting one of the components in a conventional computer will typically bring computation to a halt.”
Simulating networks
Although neural networks can be built from wires and transistors, according to Schwartz, “Ninety-nine percent of what people talk about in neural nets are really software simulations of neural nets run on conventional processors.” Simulating a neural network means mathematically defining the nodes (processors) and weights (adaptive coefficients) assigned to it. “The processing that each element does is determined by a mathematical formula that defines the element’s output signal as a function of whatever input signals have just arrived and the adaptive coefficients present in the local memory,” explains Robert Hecht-Nielsen, president of Hecht-Nielsen Neurocomputer Corp.
Some companies, such as Hecht- Nielsen Neurocomputer in San Diego, Synaptics Inc. in San Jose, Calif., and most recently Nippon Electric Co., are selling specially wired boards that link to conventional computers. The neural network is simulated on the board and then integrated via software to an IBM PC-type machine.
Other companies are providing commercial software simulations of neural networks. One of the most successful is Nestor, Inc., a Providence, Rl.,-based company that developed a software package that allows users to simulate circuits on desk-top computers. So far several job-specific neural networks have been developed. They include: a signature-verification system; a network that reads handwritten numbers on checks; one that helps screen mortgage loans; a network that identifies abnormal heart rates; and another that can recognize 11 different aircraft, regardless of the observation angle.
Several military contractors including Bendix Aerospace, TRW, and the University of Pennsylvania are also going ahead with neural networks for signal processing-training networks to identify enemy vehicles by their radar or sonar patterns, for example.
Still, there are some groups concentrating on neural network chips. At Bell Laboratories a group headed by solid-state physicist Larry Jackel constructed an experimental neural-net chip that has 75,000 transistors and an array of 54 simple processors connected by a network of resistors. The chip is about the size of a dime. Also developed at Bell Labs is a chip containing 14,400 artificial neurons made of light-sensitive amorphous silicon and deposited as a thin film on glass. When a slide is projected on the film several times, the image gets stored in the network. If the network is then shown just a small part of the image, it will reconstruct the original picture.
Finally, at Synaptics, CalTech’s Carver Mead is designing analog chips modeled after human retina and cochlea.
According to Scott E. Fahlman, a senior research scientist at Carnegie Mellon University in Pittsburgh, Pa., “building a chip for just one network can take two or three years.” The problem is that the process of laying out all the interconnected wires requires advanced techniques. Simulating networks on digital machines allows researchers to search for the best architecture before committing to hardware.
Cheap imitation
”There are at least fifty different types of networks being explored in research or being developed for applications,” says Hecht-Nielsen. ”The differences are mainly in the learning laws implemented and the topology [detailed mapping] of the connections.” Most of these networks are called “feed-forward” networks-information is passed forward in the layered network from inputs to hidden units and finally outputs.
John Hopfield is not sure this is the best architecture for neural nets. “In neurobiology there is an immense amount of feedback. You have connections coming back through the layers or interconnections within the layers. That makes the system much more powerful from a computational point of view.”
That kind of criticism brings up the question of how closely neural networks need to model the brain. Fahlman says that neural-network researchers and neurobiologists are “loosely coupled.” “Neurobiologists can tell me that the right number of elements to think about is tens of billions. They can tell me that the right kind of interconnection is one thousand or ten thousand to each neuron. And they can tell me that there doesn’t seem to be a lot of flow backward through a neuron,” he says. But unfortunately, he adds, “they can’t provide information about exactly what’s going on in the synapse of the neuron.”
Neural networks, according to the DARPA study, are a long way off from achieving the connectivity of the human brain; at this point a cockroach looks like a genius. DARPA projects that in five years the electronic “neurons” of a neural network could approach the complexity of a bee’s nervous system. That kind of complexity would allow applications like stealth aircraft detection, battlefield surveillance, and target recognition using several sensor types. “Bees are pretty smart compared with smart weapons,” commented Craig I. Fields, deputy director of research for the agency. “Bees can evade. Bees can choose routes and choose targets.”

Some text has been edited to match contemporary standards and style.
