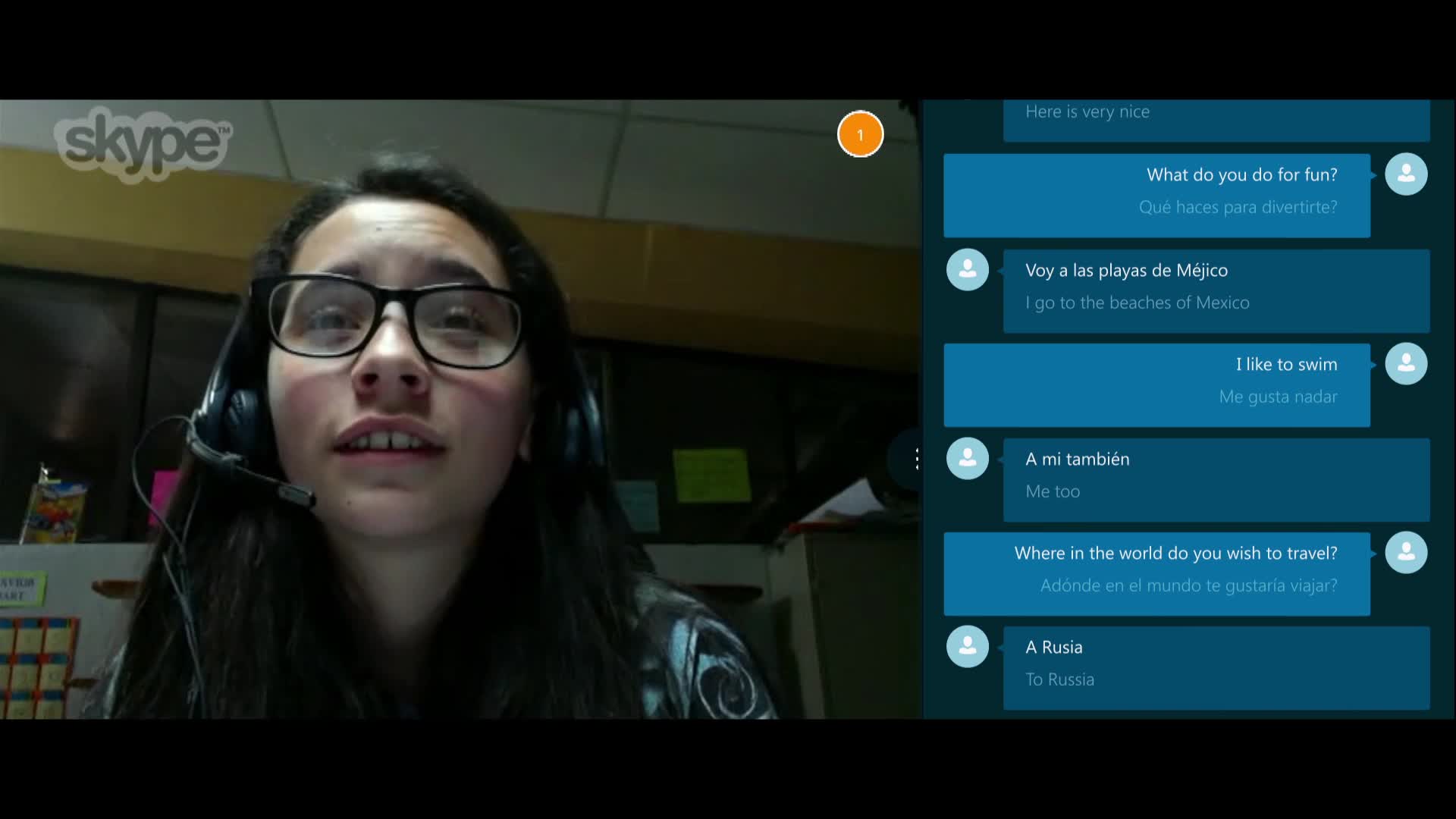
Earlier this week, roughly 50,000 Skype users woke up to a new way of communicating over the Web-based phone- and video-calling platform, a feature that could’ve been pulled straight out of Star Trek. The new function, called Skype Translator, translates voice calls between different languages in realtime, turning English to Spanish and Spanish back into English on the fly. Skype plans to incrementally add support for more than 40 languages, promising nothing short of a universal translator for desktops and mobile devices.
The product of more than a decade of dedicated research and development by Microsoft Research (Microsoft acquired Skype in 2011), Skype Translator does what several other Silicon Valley icons—not to mention the U.S. Department of Defense—have not yet been able to do. To do so, Microsoft Research (MSR) had to solve some major machine learning problems while pushing technologies like deep neural networks into new territory.
Their lofty goal: To make it possible for every human on Earth to communicate with any other human on Earth
Their lofty goal: To make it possible for any human on Earth to communicate with any other human on Earth, with no linguistic divide. “Skype has always been about breaking down barriers,” says Gurdeep Pall, Skype’s corporate vice president. “We think with Skype Translator we’ll be able to fill a gap that’s existed for a long time, really since the beginning of human communication.”
Microsoft has a long institutional relationship with machine translation, one that reaches back to MSR’s earliest days. The machine learning group is one of the oldest within MSR, says MSR Strategy Director Vikram Dendi. Bill Gates funded the group and made it a priority.
The “a computer on every desk and in every home” mantra that ruled Microsoft’s thinking at the time created an challenge for MSR. More data was being created in more places—and in more languages—than every before, Dendi says, and Microsoft researchers were tasked with creating translation engines to tackle the problem. To this day, Dendi says, one of the largest troves of untouched machine-translated text on the Internet is Microsoft’s help forums, which are translated into dozens of languages using translation engines developed in-house.
But that’s text. Translating spoken language—and especially doing so in real time—requires a whole different set of tools. Spoken words aren’t just a different medium of linguistic communication; we compose our words differently in speech and in text. Then there’s inflection, tone, body language, slang, idiom, mispronunciation, regional dialect and colloquialism. Text offers data; speech and all its nuances offers nothing but problems.
Half a beat after you stop speaking, an audio translation plays
To create a working speech-to-speech translation technology, MSR researchers knew they would have to teach their system to not only translate one word to the same word in another language based on a standard set of rules, but to understand the meaning of words and sentences. They would have to teach the machine, and the machine would have to learn.
There’s more than one way to train a computer on language, says MSR Corporate Vice President Peter Lee, but there’s also more than one way for human language to trip up a computer. MSR took a multi-faceted approach. “It’s combination of understanding the language—syntax and structure and meaning—but also a statistical matching process,” he says. “If I say ‘I like ice cream,’ you know that it probably means what it means. But if I say ‘oh, that fumble was the straw that broke the camel’s back,’ if you do a word-for-word translation into another language it probably wouldn’t make much sense.”
This gets at the core of the machine translation problem: understanding and translating meaning, not just words. MSR researchers get around this by mapping words and whole phrases across languages using statistical probability. They started building their body of knowledge using text, any text that’s already been translated—textbooks, EU parliament speeches, etc. That allows the translation engine to set a baseline and begin figuring out which phrases—even those that don’t translate literally—overlap.
To translate an English phrase like “the straw that broke the camel’s back” into, say, German, the system looks for probabilistic matches, selecting the best solution from a number of candidate phrases based on what it thinks is most likely to be correct. Over time the system builds confidence in certain results, reducing errors. With enough use, it figures out that an equivalent phrase, “the drop that tipped the bucket,” will likely sound more familiar to a German speaker.
This kind of probabilistic, statistical matching allows the system to get smarter over time, but it doesn’t really represent a breakthrough in machine learning or translation (though MSR researchers would point out that they’ve built some pretty sophisticated and unique syntax parsing algorithms into their engine). And anyhow, translation is no longer the hardest part of the equation. The real breakthrough for real-time speech-to-speech translation came around in 2009, when a group at MSR decided to return to deep neural network research in an effort to enhance speech recognition and synthesis—the turning of spoken words into text and vice versa.
Designed more like the human brain than a classical computer
Deep neural networks (DNNs)—biologically inspired computing paradigms designed more like the human brain than a classical computer—enable computers to learn observationally through a powerful process known as deep learning. But at the beginning of the last decade building DNN-based systems proved difficult. Many researchers turned to other solutions with more near-term promise.
For something like a decade, machine translation performance stagnated. “There was a full 10-year period in which we were working really hard and discovering new things every day, but the quality of our system wasn’t improving,” Lee says. “Then we finally hit a tipping point.” MSR had never fully walked away from DNN research, and when a group of machine translation researchers began actively pursuing them as a means of creating faster, more efficient speech recognition engines, they experienced the breakthrough they’d long sought. DNN technology had come a long way, and scientists at MSR and elsewhere had by this point been able to develop sophisticated machine learning models via DNNs that performed more like neurons in the human brain than traditional computers. “Returning to DNNs was crucial,” Dendi says. “If there is a single breakthrough, that’s it.”
New DNN-based models that learn as they go proved capable of building larger and more complex bodies of knowledge about the data sets they were trained on—including things like language. Speech recognition accuracy rates shot up by 25 percent. Moreover, DNNs are fast enough to make real-time translation a reality, as 50,000 people found out this week.
Not that users would notice. All this technological wizardry happens in the background. When one party on a Skype Translator call speaks, his or her words touch all of those pieces, traveling first to the cloud, then in series through a speech recognition system, a program that cleans up unnecessary “ums” and “ahs” and the like, a translation engine, and a speech synthesizer that turns that translation back into audible speech. Half a beat after that person stops speaking, an audio translation is already playing while a text transcript of the translation displays within the Skype app.
Skype Translator isn’t perfect. It still gets hung up on idioms it doesn’t understand, or turns of phrases that are uncommon, or the fact that most of us speak our mother tongues with a certain degree of disregard for proper pronunciation, sentence structure, or diction. Lee and his colleagues at Skype aren’t bothered by this. They’re more interested to see how the system evolves with tens of thousands of users not only testing its limitations but teaching it new aspects of speech and human interaction that MSR hasn’t yet considered.
“We feel pretty good about it,” Lee says. “But when this thing gets out in the wild, who knows what happens?”
