
Researchers are training robots to perform an ever-growing number of tasks through trial-and-error reinforcement learning, which is often laborious and time-consuming. To help out, humans are now enlisting large language model AI to speed up the training process. In a recent experiment, this resulted in some incredibly dexterous albeit simulated robots.
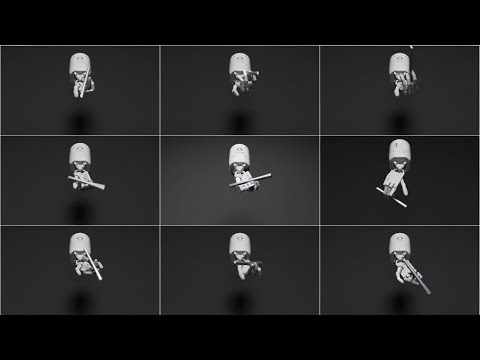
A team at NVIDIA Research directed an AI protocol powered by OpenAI’s GPT-4 to teach a simulation of a robotic hand nearly 30 complex tasks, including tossing a ball, pushing blocks, pressing switches, and some seriously impressive pen-twirling abilities.
Eureka! Extreme Robot Dexterity with LLMs | NVIDIA Research Paper
[Related: These AI-powered robot arms are delicate enough to pick up Pringles chips.]
NVIDIA’s new Eureka “AI agent” utilizes GPT-4 by asking the large language model (LLM) to write its own reward-based reinforcement learning software code. According to the company, Eureka doesn’t need intricate prompting or even pre-written templates; instead, it simply begins honing a program, then adheres to any subsequent external human feedback.
In the company’s announcement, Linxi “Jim” Fan, a senior research scientist at NVIDIA, described Eureka as a “unique combination” of LLMs and GPU-accelerated simulation programming. “We believe that Eureka will enable dexterous robot control and provide a new way to produce physically realistic animations for artists,” Fan added.
Judging from NVIDIA’s demonstration video, a Eureka-trained robotic hand can pull off pen spinning tricks to rival, if not beat, extremely dextrous humans.
After testing its training protocol within an advanced simulation program, Eureka then analyzes its collected data and directs the LLM to further improve upon its design. The end result is a virtually self-iterative AI protocol capable of successfully encoding a variety of robotic hand designs to manipulate scissors, twirl pens, and open cabinets within a physics-accurate simulated environment.
Eureka’s alternatives to human-written trial-and-error learning programs aren’t just effective—in most cases, they’re actually better than those authored by humans. In the team’s open-source research paper findings, Eureka-designed reward programs outperformed humans’ code in over 80 percent of the tasks—amounting to an average performance improvement of over 50 percent in the robotic simulations.
[Related: How researchers trained a budget robot dog to do tricks.]
“Reinforcement learning has enabled impressive wins over the last decade, yet many challenges still exist, such as reward design, which remains a trial-and-error process,” Anima Anandkumar, senior director of AI research at NVIDIA’s senior director of AI research and one of the Eureka paper’s co-authors, said in the company’s announcement. “Eureka is a first step toward developing new algorithms that integrate generative and reinforcement learning methods to solve hard tasks.”
