Efficient New Object Recognition Software Uses Smarter Piece-By-Piece Approach
A new visual recognition program developed at MIT uses a process of elimination to identify objects much more efficiently than...
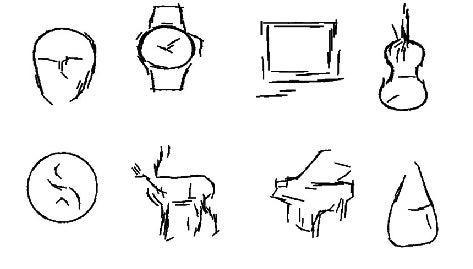
A new visual recognition program developed at MIT uses a process of elimination to identify objects much more efficiently than the matching techniques used by existing software. Line by line, piece by piece, it identifies commonalities between everyday objects, resulting in line drawings that resemble an artist’s sketch.
Unlike other object-recognition programs, it doesn’t need to be trained to look for specific features — say, eyes, a nose and a mouth. Rather, it starts with small lines, searching for basic visual cues shared by multiple examples of the same object. Then it looks for combinations of those features shared by multiple examples, and then combinations of those combinations, and so on.
The result is a catalog of parts that combine to form a model of an object. Once the catalog is assembled, the system goes backward, throwing out all redundancies.
MIT provides this example for a profile of a horse: The second layer from the top might include two different representations of the horse’s rear: One could include the rump, one rear leg and part of the belly; the other might include the rump and both rear legs. But it could turn out that in the vast majority of cases where the system identifies one of these ‘parts,’ it identifies the other as well. So it will simply cut one of them out of its hierarchy.”
Different objects can share parts, saving plenty of computer memory. A horse and a deer have shapes in common, for instance. If you think about it, the same is essentially true for a horse and a car.
Whenever a basic shape is shared between two or more objects, the computer only needs to remember it once. The more objects, the more efficient the recognition becomes — as the researchers added more objects to the system, the average number of parts per object declined, the researchers say.
This is a major distinction from other object-recognition systems, which look for a set list of key features. A facial-recognition program might look for things that resemble eyes, noses and mouths, for instance, and determine whether they are spaced properly. But they can be hilariously inaccurate.
They also require human intuition. For each object, a programmer must determine which parts are the most important — in the case of a horse, is it the head, the neck or the rump? For a car, should the computer emphasize the wheels, the windshield or the chassis?
The new system does not have to be trained in advance to recognize certain parts. It trains itself.
It’s not as fast or as accurate as the human brain, but the recognition process shares some characteristics with the brain’s visual centers, the researchers say.
Tai Sing Lee, an associate professor of computer science at Carnegie Mellon University, points out in an MIT release that visual processing in humans involves a hierarchy of five to seven brain regions, but no one is sure what they do.
The MIT software doesn’t specify the number of layers in each catalog — it uses as many layers as it needs. It turns out that it typically needs five to seven layers. Lee said that suggests the system’s visual process might work the same way as the brain’s.
Researchers at MIT and UCLA will present their findings in June at the Institute of Electrical and Electronics Engineers’ Conference on Computer Vision and Pattern Recognition.