Omnity Makes Sense Of The World’s Messy Documents
Scanning for commonalities
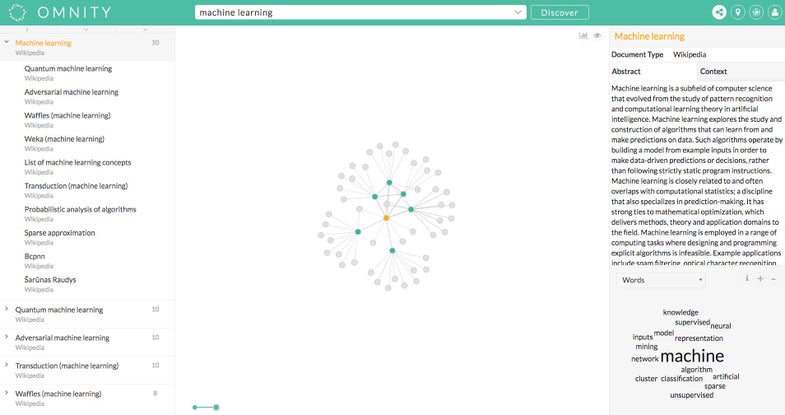
Omnity, launching today, is a search tool for knowledge. If Facebook wants to connect the world, and Google wants to make the world’s data accessible, then Omnity lies somewhere in the middle. Instead of searching the internet at large, it skims a vast library of documents ranging from scientific journals, the Library of Congress, SEC filings, and pharmaceutical trials. What makes Omnity special is the way that it analyzes these documents when they go into the platform. An algorithm finds uncommon words within the document and uses them to organize similar documents together. Instead of a list of results, Omnity presents a visual web of information, showing how each source is related to another.
When a user searches for a term like “machine learning,” Omnity not only serves results specifically related to the topic, but also adjacent topics like adversarial machine learning . It also generates a word cloud of related information, found in closely correlated documents. You can also view articles on a timeline, to see how subjects have changed over time.
Omnity wants to be useful for knowledge workers—people who read a bunch of information and then make decisions. The word cloud, as an example, is useful because it supplies related topics that might not have been apparent in the initial search. If I search machine learning, unless I’m familiar with the big picture already, I might not know to look into related subjects, such as unsupervised machine learning. Omnity offers a way of expanding the user’s field of vision.
The software works by pulling out rare words—it automatically throws out the most common words like “it” and “the” (and “and” for that matter). The unique words that define the document are used to link that document to others that incorporate similar words, phrases, or ideas.
Users can upload their own documents to create personalized libraries of knowledge. The algorithm scans the data they upload and adds it to the web it has already woven. With this feature, a law firm could upload all of their private case files, making them entirely connected and searchable (by them only). Users can also subscribe for access to specialized fields of knowledge, like paid medical journals or technical papers.
The base version of Omnity is free, but starts at $99/month for specialized information and enterprise features.